Contribute to the DSpace Development Fund
The newly established DSpace Development Fund supports the development of new features prioritized by DSpace Governance. For a list of planned features see the fund wiki page.
Duplication detection may or may not be in DSpace 7
Per discussion in our meeting on Sept 28, 2017, this tool should initially be considered a DSpace 7 add-on. While we hope to include this in the final scope of the DSpace 7 Submission process, we have said we will keep our initial DSpace 7 release closer to the features of DSpace 6. As this is a new feature, we need to determine if it's implementation will be problematic in the given timelines and/or whether it would simply be released as a optional "beta" (disabled by default) feature.
Nonetheless, we encourage feedback on the designs of this feature. We feel this is a useful DSpace feature for the future, whether it makes it into the DSpace 7 release or a later release.
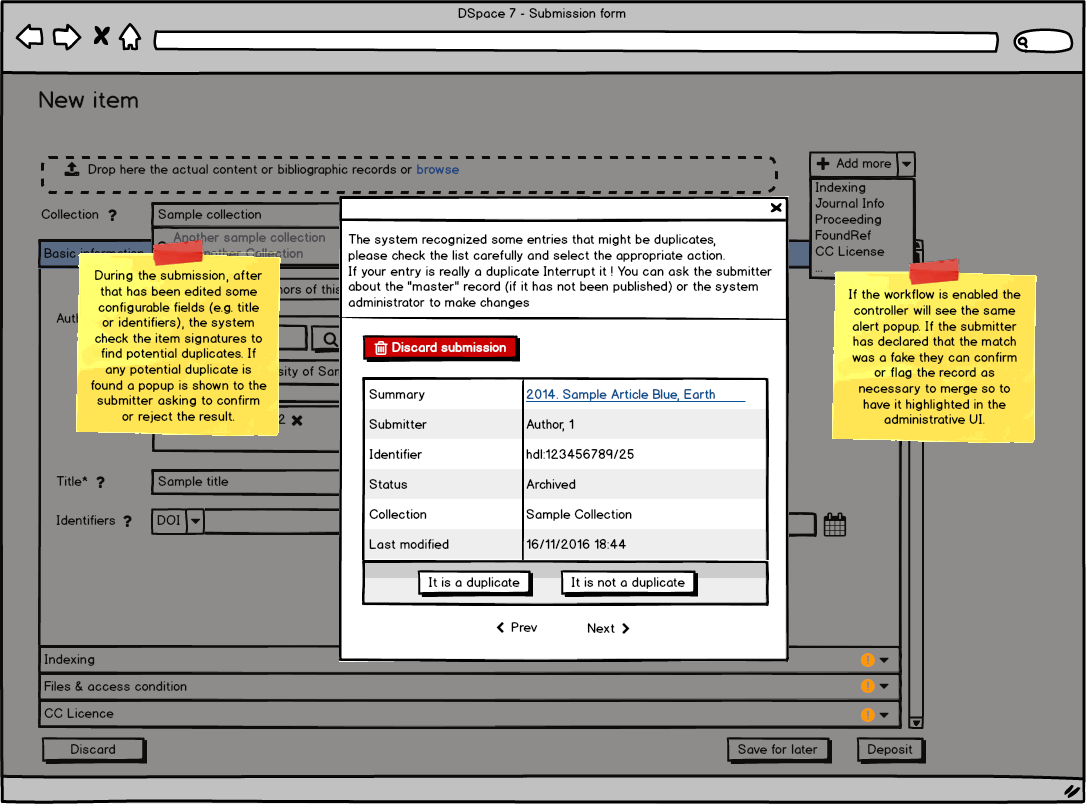
The functionality will be based on the already existent implementation available in DSpace-CRIS see (The administrative UI, deduplication alert).
The functionality is largely inspired by the SOLR official de-duplication approach, for each item one or more signatures are computed using pluggable implementation.
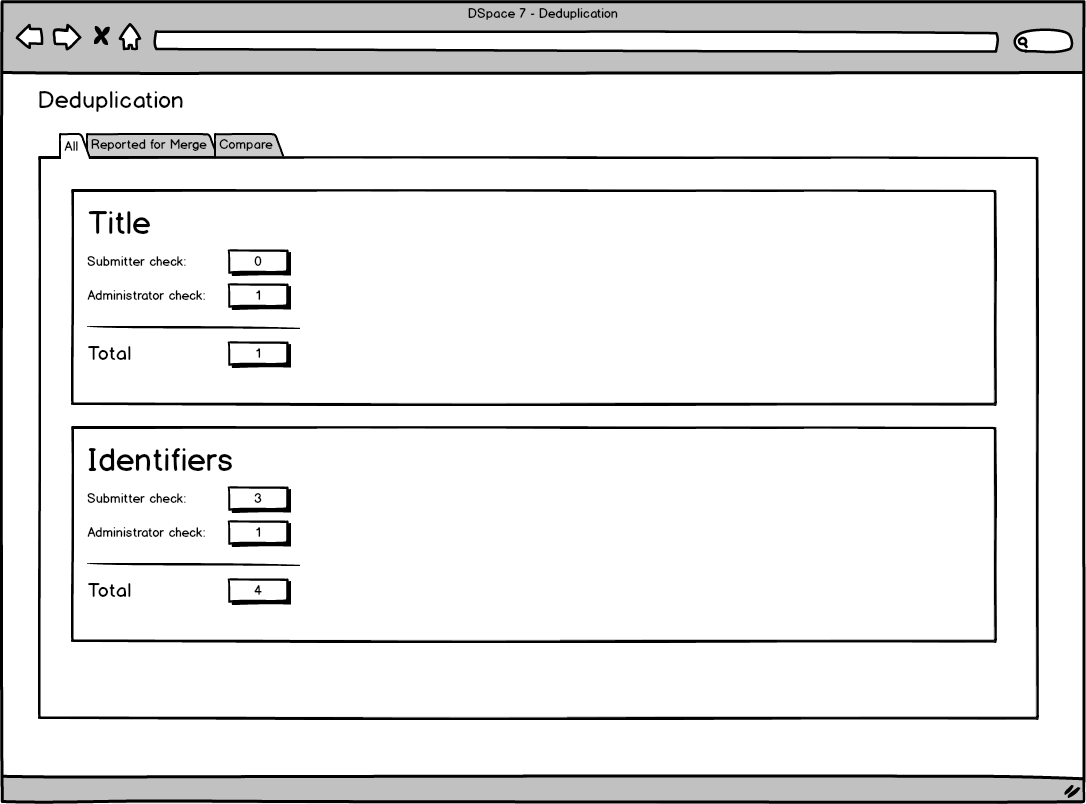
A signature is a value that summarize the information in the item using a pluggable transformation (case insensitive, ascii transcription, identifier normalisation, etc), out of box implementation based on a normalization of a single metadata (such as an identifier or the title) or a combination of metadata (such as title + year, etc.) are included.
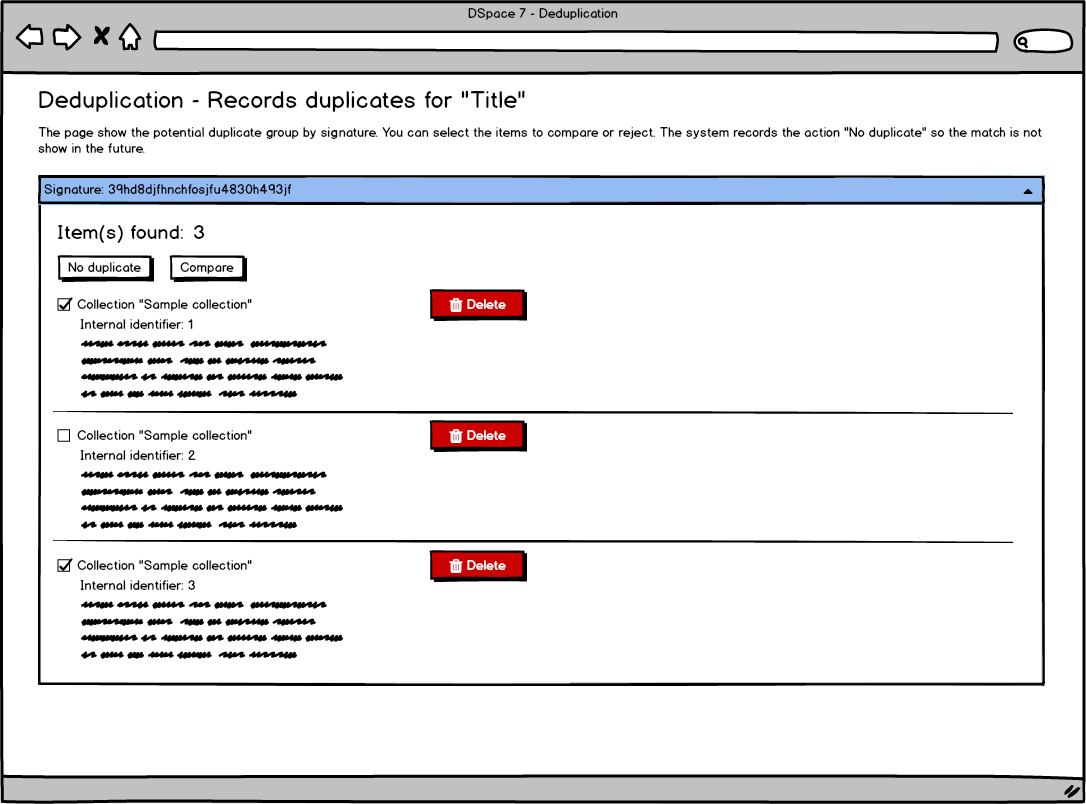
Two items are flagged as potential matches if they share at least one signature.
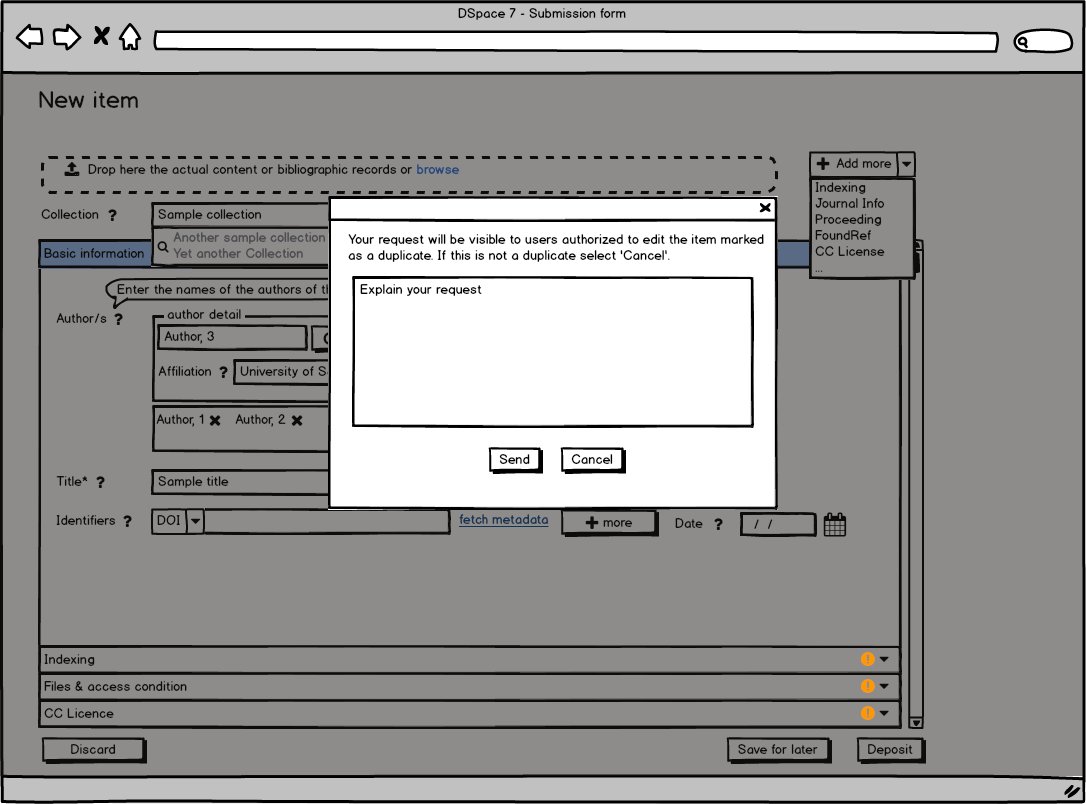
Feedback on potential matches (reject or duplicate flag) are stored in the database table dedup_reject
Signatures and matched groups are computed when an item is updated and stored on a dedicated SOLR core this make extremely fast and lightweight to check for potential duplicate. This SOLR core is maintained using DedupEventConsumer a script DedupClient is provided to rebuild the index or build it the first time if you are migrating from a previous version.
Two functionality have two point of interaction with the users
- During the submission and the workflow, the potential duplicates are presented and feedback from the submitter and validator are collected
- An administrative dashboard is available to the administrator to check for existent duplicates and merge group of items
Below the initial wireframes:
Edit form Deduplication functionalities (editable mockups)
Edit form Deduplication functionalities (editable mockups)
Edit form Deduplication functionalities (editable mockups)
Edit form Deduplication functionalities (editable mockups)
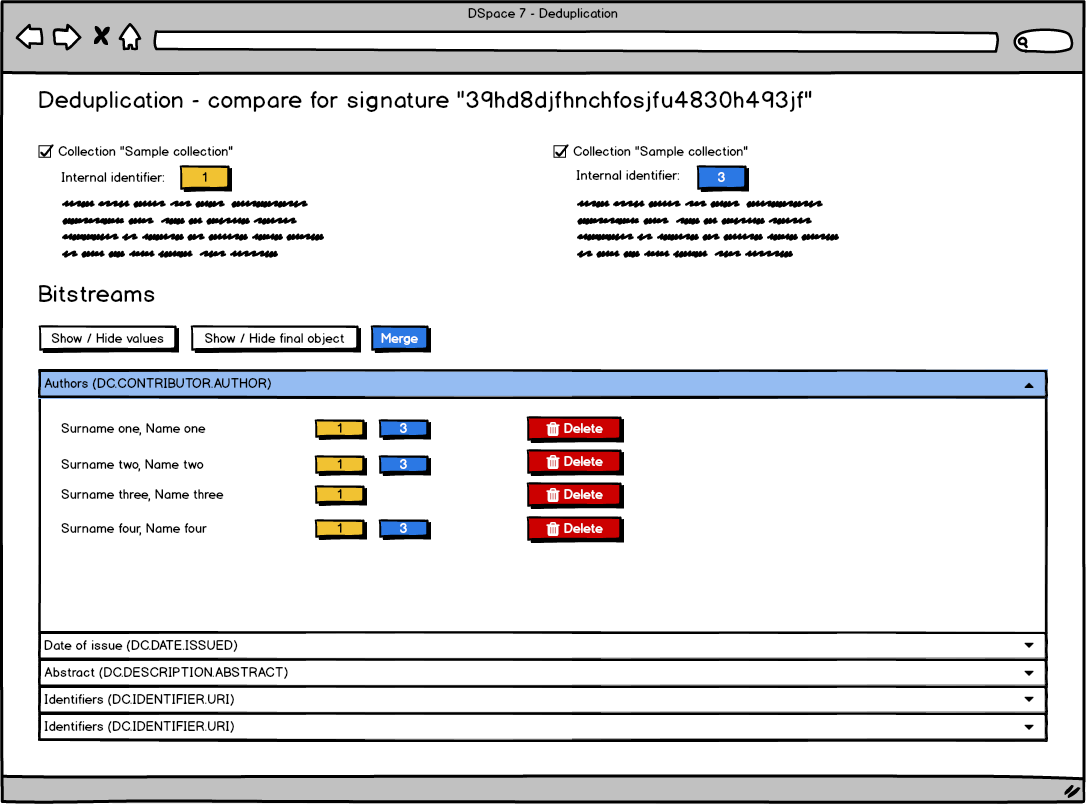
Overview
Content Tools
All content on the LYRASIS Wiki is licensed under the CC BY (Attribution) license![]() , unless otherwise noted.
, unless otherwise noted.
1 Comment
Tim Donohue
Feedback per the meeting on 2017-09-21:
Additional notes on some of the ANSWERs above can be found in the notes from our meeting on 2017-09-28