Purpose
The VIVO architectural fly-in was focused on bringing an architecturally-minded team together who individually represent distinct VIVO stakeholder constituencies for the purpose of developing architectural approaches required to address the direction of the project. The primary goal of the two-day face-to-face meeting was to assess and document a plan for improving the VIVO application architecture towards enabling and realizing the technical efforts defined in the "Statement on VIVO's Product Direction for 2019".
Participants
- Huda Khan
- Andrew Woods
- Brian Lowe
- Justin Littman
- Ralph O'Flinn
- Benjamin Gross
- Jim Blake
- Richard Outten
- Alex Viggio

Leading up to the face-to-face meeting, the team convened six conference calls over two months with the goals of establishing a common understanding of:
- the purpose of the effort as well as
- the perspectives held by each team member.
In addition to collecting requirements, assessing existing features, sharing documentation resources, and drilling into areas of exploration, each team member provided hypothetical architectural diagrams which informed the face-to-face discussions.
Goals
At the beginning of the fly-in, the team defined and agreed on the following goals:
- Translating the Statement of VIVO's Product Direction for 2019 into an actionable architecture
- Engaging and incorporating technical efforts from parts of the VIVO community that have emerged adjacent to the core application
- Evolving VIVO into a more modular, cloud-ready application. This includes defining modules that can be deployed as separate services (containerized) as well as enabling the replacement of those modules with standard cloud services (AWS Neptune, Azure Cosmos DB, etc)
- Ensuring continuity for the community in order to facilitate incremental, manageable change.
Logistics
Great effort was put towards making sure that the discussions were open and supportive, and that there was space for the voices of all team members. Ground rules were established around:
- maintaining topic-focused discussions
- time-boxing sessions
- establishing goals for each session, and
- reviewing actions/takeaways from each session
The fly-in took place over the course of two days, starting at 9am and concluding at 5:30pm, followed by team dinners.
Topics
Ingest
Requirements
- Ingest must support varied and currently unknown data sources
- Ingest must be scalable: the use of different backend triplestores or datastores must be allowed to support site-specific scaling requirements
- Ingest must support both JSON and RDF (note: JSON content must have a known mapping to RDF model)
- Content must be validated before being ingested. Example validation mechanisms: SHACL, ShEx, JSON Schema
- Ingest must expect models/shapes that are expected and able to be validated (note: initial models can be derived from what is in use in Freemarker UI)
- Ingest tooling must support two modes of operation: hands-free (automated) and curated
- Ingest tooling must support curation of data prior to ingest: disambiguation and reconciliation of entities
- Ingest will be entity-centric vs triple-centric. Example entities: Person, Grant, Publication, Authorship
- Ingest tooling must not require the use of a specific programming language
- Ingest must support realtime, incremental updates
Out of scope
- Extraction of data from data sources
- Transformation of data from data sources
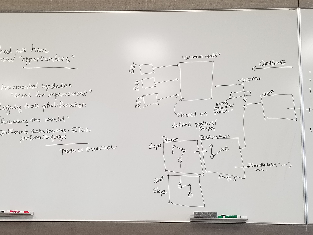
Below: DS1-3: Data sources, read in and validated based on “shapes” (or patterns or sets of triples representing entities), with entity resolution/URI creation as required, leading to a set of triples that can be read into VIVO. The arrow on the right side of the picture continues to VIVO in the next picture.
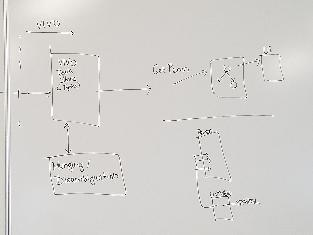
Below: The previous picture represents a view of the combine/ingest process that leads to VIVO in this picture (the munging/disambiguation box was supposed to be moved to the ingest process instead). Triples can then be requested for different entities which provide a UI. The portion on the bottom right identifies how the current VIVO system uses SPARQL queries defined in list views which together define what is expected to be displayed for specific entity types.
UI
Requirements
- Current Freemarker UI will stay in-place for the scope of this plan (although deprecated)
- UI must provide read access to VIVO data
- UI must minimally be informed by the Production Evolution effort
- UI must be based on data coming from a JSON endpoint
- UI should render data served by a GraphQL server
- GraphQL server should be configured with the same models used by ingest tooling (note: DocumentModifier.java may be updated to populate search index with these models)
- UI must support accessibility
- UI must support internationalization (i18n)
- UI should avoid querying the triplestore when rendering
Decoupling VIVO
By decoupling VIVO, we envision a collection of independent services that interact with one another over HTTP. Each of these components provide services based on well-documented contracts/APIs to further enable the replacement of one implementation of a component with another technology. Where possible, the component contracts/APIs should be aligned with native cloud services (i.e. AWS, Azure). Finally, to ensure consistent deployment environments and to facilitate transitioning from local to cloud deployment, each of the components below should be bundled as Docker images.
Triplestore
- Initial service abstraction is represented in the RDFService.java interface
- Implementations to support: Fuseki, BlazeGraph, Neptune
- Respond to SPARQL-Query
- Ingest set of triples
- Generate resource URIs
- Produce list of named graphs
- Produce serialization of single graph
- Produce serialization of entire graph store
- Determine if internal graph is different from a serialized graph
Search Index
- Initial service abstractions are represented in the following interfaces: SearchIndexer.java and SearchEngine.java
- Implementations to support: Solr, Elasticsearch, GraphQL
- Note: The search index machinery could potentially be used to transform data for import to and use in other derivative stores
Reasoners (TBox / ABox)
- Enable configuration to set reasoning to on-demand or to on-change (Brian L has example code)
Triple Pattern Fragments
- Either move current implementation into its own component, or use one of the other community implementations
Asset store
The asset store is where images are currently stored. Documents could potentially be stored via the asset store as well.
- Initial service abstraction is represented in the FileStorage.java interface
Architectural concerns and questions
- From an architectural perspective, having a triplestore at the core of the application brings significant limitations
- As we decouple components, we must ensure that we also decouple logic expectations between the components
- Is the VIVO ontology undergoing a significant revision? If so, what is the nature of the impact we should expect on the VIVO application?
Retrospective
It was suggested that we hold a similar, architectural face-to-face meeting annually, with quarterly community calls to reflect on progress and pivots.
If we hold future face-to-face meetings, the following suggestions/observations should be applied before and during the meetings.
Before
- Assign homework early in the f2f planning process for individuals to engage in deep exploration of specific topics
- Have team create architectural diagrams early in the planning process
- Best timing: Mid-February to Mid-March
- Use pre-f2f calls to establish common understandings
- Guiding principles/documents are vital, e.g. Product Direction for 2019
- Team size should be limited ~10
- Ideally bring in voices/participation from adjacent efforts to the VIVO problem space
- Ideally bring in voices/participation from practitioners, those facing real-world challenges
During
- Ensure coffee/tea/snacks are available at the venue
- Ensure whiteboards are available at the venue
- Ideal not having a projector/presentations
- Ideal to be close to an airport
- Important to have facilitation of the meeting and ground-rules
- Ideal to have collaborative agenda-setting at the beginning of the meeting based on a set of previously discussed topics
- Important to establish goals at the beginning of each session
- Important to review/summarize actions/decisions at the end of each session