The Karma data integration tool allows users to semantically model tabular data (i.e. spreadsheets) in a visual environment. The This makes it easier easy to understand the best way to map data to ontologies and provides a visual comparison to the VIVO-ISF relationship diagrams. This Ontology Diagrams This approach is especially useful for new VIVO adopters and those who prefer not to create and use their own scripts.
It's probably most common for data to be provided in spreadsheet format, which can be very simple to transform into RDF if each column of every row refers to attributes of the same entity, usually identified by a record identifier. The process becomes more complicated if different cells in the same row of the spreadsheet refer to different entities. This page includes example tabular datasets and screenshots of models created in using Karma.
Modeling
...
organizations,
...
people, and
...
positions
The following spreadsheet would be of organizations (one organization per row) is very easy to load into a VIVO describing organizational units:

You can readily imagine storing representing the information about each organizational unit organization – id, name, and the contact information, and web site address – in additional columns. The Unique Resource Identifier (URI) that used by VIVO to identify each organizational unit can be generated by using the org_ID and the institutional VIVO namespace. This in fact is the starting point of creating the basic structure of your VIVO data.
The next step is to store the information about people affiliated with those organizational units, and finally, their positions within those units.
A spreadsheet of people data will look typically looks like this:

In this spreadsheet the person identifier is called UID (your institution will have a different name for this identifier) and is the unique identifier for a person at your institution, by which that person is uniquely identified in all databases at the specific your institution. NETID (your institution will have a different name for this identifier) is another identifier for a person, often used as a username for logging into university systems. The other columns are self explanatory. The
In Karma, the model of this data set containing people information is shown in the image below:
...
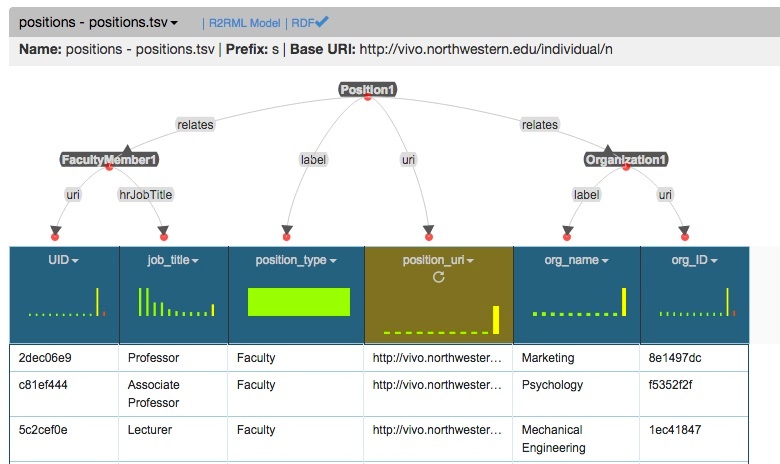
A spreadsheet of people’s positionpositions in the organization will look like this:
...
The model of this data set containing information about people's positions within an institution is shown in the image below:
Modeling Academic Articles
A spreadsheet of academic articles , however, would be is more complicated:

In this spreadsheet we have two important identifiers to connect the person with the article he/she authored: the articleID and the UID. Article ID can be any unique identifier assigned to the article. A model of this data set containing information about academic articles is shown in the image below:
...
You must also assign a unique URI to these extra classes, shown below as URIs with the '_role' suffix in the gold columns. Below, the National Science Foundation has been modeled as vivo:GovernmentAgency. If you have a wide variety of funding organization types on a single spreadsheet source, you may want to create a separate spreadsheet and model for your funding organizations, or generalize the type to vivo:FundingOrganization. Likewise with the people modeled as vivo:FacultyMember below, you may generalize to foaf:Person.

Using PyTransform to create URI
Karma's PyTransform capability allows you to transform your source data using Python. A common use of PyTransform is to create additional unique URIs based off an existing one. The URIs with the '_role' suffix above were created using this Python code:
...
More information on PyTransform is available here within Karma's documentation.
One example when you will need to use the PyTransform option is to create the position URI in order to create the needed triples for representing each person position within his/her institution. As you can see above in the people's position data example there are few columns that you need the values from to create the correct triples for the position. In the drop down menu found on each column you select the PyTransform option and in the window you type:
...
return "http://vivo.northwestern/position/n"+getValue("UID")+"_"+getValue("org_ID")+"_"+getValue("position_type").replace(" ","_")
In this case the first part of the URI is the Northwestern University namespace which you need to change to your own namespace
...
, such as http://vivo.school.edu/
...
individual/n and then select values from three columns as shown above. Selecting values from three columns is
...
necessary to identify positions uniquely, since most likely you have people at your institution that have multiple appointments and this allows you to create separate triples for each of their multiple positions within your institution.
Another example when you will need to use the PyTransform option is when you create the authorship URI for modeling the publications
...
data as shown above. To do that you would want to select the PyTransform window found on the drop down menu on each column. Once you open the PyTransform window you type in the following:
...
return "http://vivo.northwestern.edu/authorship/n"+getValue("ID")+getValue("uuid").replace(" ","_")
The first part is your namespace and you would want to change that with your own namespace
...
. The "ID" and the "uuid" are the names of the columns from which we have decided to create the authorship URI and they represent the article unique ID and the person unique ID respectively.
...
External links
- Karma Documentation
- Videos on using Karma for VIVO by Violeta Ilik
- Video on using Karma for VIVO by Pedro Szekely
...