All Versions
- DSpace 7.x (Current Release)
- DSpace 8.x (Unreleased)
- DSpace 6.x (EOL)
- DSpace 5.x (EOL)
- More Versions...
Old Release
This documentation relates to an old version of DSpace, version 4.x. Looking for another version? See all documentation.
This DSpace release is end-of-life and is no longer supported.
This page explains various customization and configuration options that are available within DSpace for the Item Submission user interface.
The DSpace Submission process consists of a series of "steps", where each "step" corresponds to one or more UI pages. By default, the DSpace Submission process includes the following steps, in this order:
[dspace]/config/default.license file. It can also be customized per-collection from the Collection Admin UI.To modify or reorganize these submission steps, just modify the [dspace]/config/item-submission.xml file. Please see the section below on Reordering/Removing/Adding Submission Steps.
You can also choose to have different submission processes for different DSpace Collections. For more details, please see the section below on Assigning a custom Submission Process to a Collection.
DSpace 4.0 has removed the "Initial Questions" step by default
Prior to DSpace 4.0, the "Initial Questions" step preceded all "Describe" steps. However, it was removed by default in DSpace 4.0.
You may still choose to re-enable the "Initial Questions" step, as needed. However, please note the warning below about the auto-assigning of Dates in the "Initial Questions" step.
DSpace also ships with several optional steps which you may choose to enable if you wish. In no particular order:
Published Before: The item has been published or publicly distributed before (If selected, then users will be asked for a publication date and publisher in the Describe step).
Initial Questions will auto-assign a publication date when "Published Before" is unselected
Please note, if you enable Initial Questions, and your users do NOT select "Published Before" option, then DSpace will auto-assign a publication date (dc.date.issued) to that particular Item.
It may be entirely accurate for some types of content (e.g. for gray literature or even theses/dissertations) to auto-assign this publication date. As such, you may wish to still enable "Initial Questions" if your repository is mainly for previously unpublished content. You may also choose to only enable it for specific Collections – see Assigning a custom Submission Process to a Collection section below.
However, if the Item actually was published in some other location, this will result in an incorrect publication date being reported by DSpace. This tendency for an incorrect publication date has been reported by Google Scholar to DSpace developers (see: DS-1481), which is why the "Initial Questions" are now disabled by default (see DS-1655).
To enable any of these optional submission steps, just uncomment the step definition within the [dspace]/config/item-submission.xml file. Please see the section below on Reordering/Removing/Adding Submission Steps.
You can also choose to enable certain steps only for specific DSpace Collections. For more details, please see the section below on Assigning a custom Submission Process to a Collection.
The [dspace]/config/item-submission.xml contains the submission configurations for both the DSpace JSP user interface (JSPUI) or the DSpace XML user interface (XMLUI or Manakin). This configuration file contains detailed documentation within the file itself, which should help you better understand how to best utilize it.
<item-submission> <!-- Where submission processes are mapped to specific Collections --> <submission-map> <name-map collection-handle="default" submission-name="traditional" /> ... </submission-map> <!-- Where "steps" which are used across many submission processes can be defined in a single place. They can then be referred to by ID later. --> <step-definitions> <step id="collection"> <processing-class>org.dspace.submit.step.SelectCollectionStep</process;/processing-class> <workflow-editable>false</workflow-editable> </step> ... </step-definitions> <!-- Where actual submission processes are defined and given names. Each <submission-process> has many <step> nodes which are in the order that the steps should be in.--> <submission-definitions> <submission-process name="traditional"> ... <!-- Step definitions appear here! --> </submission-process> ... </submission-definitions> </item-submission>
Because this file is in XML format, you should be familiar with XML before editing this file. By default, this file contains the "traditional" Item Submission Process for DSpace, which consists of the following Steps (in this order):
Select Collection -> Describe -> Upload -> Verify -> License -> Complete
If you would like to customize the steps used or the ordering of the steps, you can do so within the <submission-definition> section of the item-submission.xml .
In addition, you may also specify different Submission Processes for different DSpace Collections. This can be done in the <submission-map> section. The item-submission.xml file itself documents the syntax required to perform these configuration changes.
This section describes how Steps of the Submission Process are defined within the item-submission.xml.
<step> definitions can appear in one of two places within the item-submission.xml configuration file.
For example:
<step-definitions> <step id="custom-step"> ... </step> ... </step-definitions>
For example:
<submission-process> <step> ... </step> </submission-process>
The ordering of the <step> tags within a <submission-process> definition directly corresponds to the order in which those steps will appear!
For example, the following defines a Submission Process where the License step directly precedes the Initial Questions step (more information about the structure of the information under each <step> tag can be found in the section on Structure of the <step> Definition below):
<submission-process> <!--Step 1 will be to Sign off on the License--> <step> <heading>submit.progressbar.license</heading> <processing-class>org.dspace.submit.step.LicenseStep</processing-classing-class> <jspui-binding>org.dspace.app.webui.submit.step.JSPLicenseStep</jspui-binding> <xmlui-binding>org.dspace.app.xmlui.aspect.submission.submit.LicenseStenseStep</xmlui-binding> <workflow-editable>false</workflow-editable> </step> <!--Step 2 will be to Ask Initial Questions--> <step> <heading>submit.progressbar.initial-questions</heading> <processing-class>org.dspace.submit.step.InitialQuestionsStep</process;/processing-class> <jspui-binding>org.dspace.app.webui.submit.step.JSPInitialQuestionsSteonsStep</jspui-binding> <xmlui-binding>org.dspace.app.xmlui.aspect.submission.submit.InitialQutialQuestionsStep</xmlui-binding> <workflow-editable>true</workflow-editable> </step> ...[other steps]... </submission-process>
The same <step> definition is used by both the DSpace JSP user interface (JSPUI) an the DSpace XML user interface (XMLUI or Manakin). Therefore, you will notice each <step> definition contains information specific to each of these two interfaces.
The structure of the <step> Definition is as follows:
<step> <heading>submit.progressbar.describe</heading> <processing-class>org.dspace.submit.step.DescribeStep</processing-classing-class> <jspui-binding>org.dspace.app.webui.submit.step.JSPDescribeStep</jspuilt;/jspui-binding> <xmlui-binding>org.dspace.app.xmlui.aspect.submission.submit.DescribeScribeStep</xmlui-binding> <workflow-editable>true</workflow-editable> </step>
Each step contains the following elements. The required elements are so marked:
org.dspace.submit.AbstractProcessingStep class (or alternatively, extend one of the pre-existing step processing classes in org.dspace.submit.step.*)org.dspace.app.webui.submit.JSPStep class. This property need not be defined if you are using the XMLUI interface, or for steps which only perform automated processing, i.e. non-interactive steps.org.dspace.app.xmlui.submission.AbstractSubmissionStep class. This property need not be defined if you are using the JSPUI interface, or for steps which only perform automated processing, i.e. non-interactive steps.The removal of existing steps and reordering of existing steps is a relatively easy process!
Reordering steps
<submission-process> tag which defines the Submission Process that you are using. If you are unsure which Submission Process you are using, it's likely the one with name="traditional", since this is the traditional DSpace submission process.<step> tags within that <submission-process> tag. Be sure to move the entire <step> tag (i.e. everything between and including the opening <step> and closing </step> tags).<step> defining the Review/Verify step only allows the user to review information from steps which appear before it. So, it's likely you'd want this to appear as one of your last few steps<step> defining the Initial Questions step should always appear before the Upload or Describe steps since it asks questions which help to set up those later steps.Removing one or more steps
<submission-process> tag which defines the Submission Process that you are using. If you are unsure which Submission Process you are using, it's likely the one with name="traditional", since this is the traditional DSpace submission process.<! -- and -->) the <step> tags which you want to remove from that <submission-process> tag. Be sure to comment out the entire <step > tag (i.e. everything between and including the opening <step> and closing </step> tags).Adding one or more optional steps
<submission-process> tag which defines the Submission Process that you are using. If you are unsure which Submission Process you are using, it's likely the one with name="traditional", since this is the traditional DSpace submission process.<! -- and -->) the <step> tag(s) which you want to add to that <submission-process> tag. Be sure to uncomment the entire <step> tag (i.e. everything between and including the opening <step> and closing </step> tags).Assigning a custom submission process to a Collection in DSpace involves working with the submission-map section of the item-submission.xml. For a review of the structure of the item-submission.xml see the section above on Understanding the Submission Configuration File.
Each name-map element within submission-map associates a collection with the name of a submission definition. Its collection-handle attribute is the Handle of the collection. Its submission-name attribute is the submission definition name, which must match the name attribute of a submission-process element (in the submission-definitions section of item-submission.xml.
For example, the following fragment shows how the collection with handle "12345.6789/42" is assigned the "custom" submission process:
<submission-map>
<name-map collection-handle=" 12345.6789/42" submission-name="custom" />
...
</submission-map>
<submission-definitions>
<submission-process name="custom">
...
</submission-definitions>
It's a good idea to keep the definition of the default name-map from the example input-forms.xml so there is always a default for collections which do not have a custom form set.
You will need the handle of a collection in order to assign it a custom form set. To discover the handle, go to the "Communities & Collections" page under "Browse" in the left-hand menu on your DSpace home page. Then, find the link to your collection. It should look something like:
http://myhost.my.edu/dspace/handle/12345.6789/42
The underlined part of the URL is the handle. It should look familiar to any DSpace administrator. That is what goes in the collection-handle attribute of your name-map element.
This section explains how to customize the Web forms used by submitters and editors to enter and modify the metadata for a new item. These metadata web forms are controlled by the Describe step within the Submission Process. However, they are also configurable via their own XML configuration file (input-forms.xml).
You can customize the "default" metadata forms used by all collections, and also create alternate sets of metadata forms and assign them to specific collections. In creating custom metadata forms, you can choose:
NOTE: The cosmetic and ergonomic details of metadata entry fields remain the same as the fixed metadata pages in previous DSpace releases, and can only be altered by modifying the appropriate stylesheet and JSP pages.
All of the custom metadata-entry forms for a DSpace instance are controlled by a single XML file, input-forms.xml, in the config subdirectory under the DSpace home. DSpace comes with a sample configuration that implements the traditional metadata-entry forms, which also serves as a well-documented example. The rest of this section explains how to create your own sets of custom forms.
The description of a set of pages through which submitters enter their metadata is called a form (although it is actually a set of forms, in the HTML sense of the term). A form is identified by a unique symbolic name. In the XML structure, the form is broken down into a series of pages: each of these represents a separate Web page for collecting metadata elements.
To set up one of your DSpace collections with customized submission forms, first you make an entry in the form-map. This is effectively a table that relates a collection to a form set, by connecting the collection's Handle to the form name. Collections are identified by handle because their names are mutable and not necessarily unique, while handles are unique and persistent.
A special map entry, for the collection handle "default", defines the default form set. It applies to all collections which are not explicitly mentioned in the map. In the example XML this form set is named traditional (for the "traditional" DSpace user interface) but it could be named anything.
The XML configuration file has a single top-level element, input-forms, which contains three elements in a specific order. The outline is as follows:
<input-forms>
<-- Map of Collections to Form Sets -->
<form-map>
<name-map collection-handle="default" form-name="traditional" />
...
</form-map>
<-- Form Set Definitions -->
<form-definitions>
<form name="traditional">
...
</form>
...
</form-definitions>
<-- Name/Value Pairs used within Multiple Choice Widgets -->
<form-value-pairs>
<value-pairs value-pairs-name="common_iso_languages" dc-term="language_iso">
...
</value-pairs>
...
</form-value-pairs>
</input-forms>
Each name-map element within form-map associates a collection with the name of a form set. Its collection-handle attribute is the Handle of the collection, and its form-name attribute is the form set name, which must match the name attribute of a form element.
For example, the following fragment shows how the collection with handle "12345.6789/42" is attached to the "TechRpt" form set:
<form-map>
<name-map collection-handle=" 12345.6789/42" form-name=" TechRpt"/>
...
</form-map>
<form-definitions>
<form name="TechRept">
...
</form-definitions>
It's a good idea to keep the definition of the default name-map from the example input-forms.xml so there is always a default for collections which do not have a custom form set.
You will need the handle of a collection in order to assign it a custom form set. To discover the handle, go to the "Communities & Collections" page under "Browse" in the left-hand menu on your DSpace home page. Then, find the link to your collection. It should look something like:
http://myhost.my.edu/dspace/handle/12345.6789/42
The underlined part of the URL is the handle. It should look familiar to any DSpace administrator. That is what goes in the collection-handle attribute of your name-map element.
You can add a new form set by creating a new form element within the form-definitions element. It has one attribute, name, which as seen above must match the value of the name-map for the collections it is to be used for.
The content of the form is a sequence of page elements. Each of these corresponds to a Web page of forms for entering metadata elements, presented in sequence between the initial "Describe" page and the final "Verify" page (which presents a summary of all the metadata collected).
A form must contain at least one and at most six pages. They are presented in the order they appear in the XML. Each page element must include a number attribute, that should be its sequence number, e.g.
<page number="1">
The page element, in turn, contains a sequence of field elements. Each field defines an interactive dialog where the submitter enters one of the Dublin Core metadata items.
Each field contains the following elements, in the order indicated. The required sub-elements are so marked:
For the use of controlled vocabularies see the Configuring Controlled Vocabularies section.
This feature is available for use with the XMLUI since DSpace 3.0 and with JSPUI since 3.1. A field can be made visible depending on the value of dc.type. A new field element, <type-bind>, has been introduced to facilitate this. In this example the field will only be visible if a value of "thesis" or "ebook" has been entered into dc.type on an earlier page:
<field>
<dc-schema>dc</dc-schema>
<dc-element>identifier</dc-element>
<dc-qualifier>isbn</dc-qualifier>
<label>ISBN</label>
<type-bind>thesis,ebook</type-bind>
</field>
You may notice that some fields are automatically skipped when a custom form page is displayed, depending on the kind of item being submitted. This is because the DSpace user-interface engine skips Dublin Core fields which are not needed, according to the initial description of the item. For example, if the user indicates there are no alternate titles on the first "Describe" page (the one with a few checkboxes), the input for the title.alternative DC element is automatically omitted, even on custom submission pages.
When a user initiates a submission, DSpace first displays what we'll call the "initial-questions page". By default, it contains three questions with check-boxes:
The answers to the first two questions control whether inputs for certain of the DC metadata fields will displayed, even if they are defined as fields in a custom page. Conversely, if the metadata fields controlled by a checkbox are not mentioned in the custom form, the checkbox is omitted from the initial page to avoid confusing or misleading the user.
The two relevant checkbox entries are "The item has more than one title, e.g. a translated title", and "The item has been published or publicly distributed before". The checkbox for multiple titles trigger the display of the field with dc-element equal to "title" and dc-qualifier equal to "alternative". If the controlling collection's form set does not contain this field, then the multiple titles question will not appear on the initial questions page.
DSpace now supports controlled vocabularies to confine the set of keywords that users can use while describing items. The need for a limited set of keywords is important since it eliminates the ambiguity of a free description system, consequently simplifying the task of finding specific items of information. The controlled vocabulary allows the user to choose from a defined set of keywords organised in an tree (taxonomy) and then use these keywords to describe items while they are being submitted.
The taxonomies are described in XML following this (very simple) structure:
<node id="acmccs98" label="ACMCCS98">
<isComposedBy>
<node id="A." label="General Literature">
<isComposedBy>
<node id="A.0" label="GENERAL"/>
<node id="A.1" label="INTRODUCTORY AND SURVEY"/>
...
</isComposedBy>
</node>
...
</isComposedBy>
</node>
You are free to use any application you want to create your controlled vocabularies. A simple text editor should be enough for small projects. Bigger projects will require more complex tools. You may use Protegé to create your taxonomies, save them as OWL and then use a XML Stylesheet (XSLT) to transform your documents to the appropriate format. Future enhancements to this add-on should make it compatible with standard schemas such as OWL or RDF.
New vocabularies should be placed in [dspace]/config/controlled-vocabularies/ and must be according to the structure described.
Vocabularies need to be associated with the correspondant DC metadata fields. Edit the file [dspace]/config/input-forms.xml and place a "vocabulary" tag under the "field" element that you want to control. Set value of the "vocabulary" element to the name of the file that contains the vocabulary, leaving out the extension (the add-on will only load files with extension "*.xml"). For example:
<field>
<dc-schema>dc</dc-schema>
<dc-element>subject</dc-element>
<dc-qualifier></dc-qualifier>
<repeatable>true</repeatable>
<label>Subject Keywords</label>
<input-type>onebox</input-type>
<hint>Enter appropriate subject keywords or phrases below.</hint>
<required></required>
<vocabulary>srsc</vocabulary>
</field>
The vocabulary element has an optional boolean attribute closed that can be used to force input only with the Javascript of controlled-vocabulary add-on. The default behaviour (i.e. without this attribute) is as set closed="false". This allow the user also to enter the value in free way.
The following vocabularies are currently available by default:
Finally, your custom form description needs to define the "value pairs" for any fields with input types that refer to them. Do this by adding a value-pairs element to the contents of form-value-pairs. It has the following required attributes:
Each value-pairs element contains a sequence of pair sub-elements, each of which in turn contains two elements:
Here is a menu of types of common identifiers:
<value-pairs value-pairs-name="common_identifiers" dc-term="identifier">
<pair>
<displayed-value>Gov't Doc #</displayed-value>
<stored-value>govdoc</stored-value>
</pair>
<pair>
<displayed-value>URI</displayed-value>
<stored-value>uri</stored-value>
</pair>
<pair>
<displayed-value>ISBN</displayed-value>
<stored-value>isbn</stored-value>
</pair>
</value-pairs>
It generates the following HTML, which results in the menu widget below. (Note that there is no way to indicate a default choice in the custom input XML, so it cannot generate the HTML SELECTED attribute to mark one of the options as a pre-selected default.)
<select name="identifier_qualifier_0">
<option VALUE="govdoc">Gov't Doc #</option>
<option VALUE="uri">URI</option>
<option VALUE="isbn">ISBN</option>
</select>
The DSpace web application only reads your custom form definitions when it starts up, so it is important to remember:
Any mistake in the syntax or semantics of the form definitions, such as poorly formed XML or a reference to a nonexistent field name, will cause a fatal error in the DSpace UI. The exception message (at the top of the stack trace in the dspace.log file) usually has a concise and helpful explanation of what went wrong. Don't forget to stop and restart the servlet container before testing your fix to a bug.
The Upload step in the DSpace submission process has two configuration options which can be set with your [dspace]/config/dspace.cfg configuration file. They are as follows:
First, a brief warning: Creating a new Submission Step requires some Java knowledge, and is therefore recommended to be undertaken by a Java programmer whenever possible
That being said, at a higher level, creating a new Submission Step requires the following (in this relative order):
org.dspace.submit.AbstractProcessingStep class and implement all methods defined by that abstract class.org.dspace.app.webui.submit.JSPStep and implement all methods defined there. It's recommended to use one of the classes in org.dspace.app.webui.submit.step.* as a reference.org.dspace.app.webui.submit.JSPStepManager classreview-[step].jsp) in the JSP submit/ directory.org.dspace.app.xmlui.submission.AbstractSubmissionSteporg.dspace.app.xmlui.submission.submit.* as referencesitem-submission.xmlconfiguration file.item-submission.xml, see the section above on Defining Steps (<step>) within the item-submission.xml.Non-interactive steps are ones that have no user interface and only perform backend processing. You may find a need to create non-interactive steps which perform further processing of previously entered information.
To create a non-interactive step, do the following:
org.dspace.submit.AbstractProcessingStep class. In this class add any processing which this step will perform.<step>
<processing-class>org.dspace.submit.step.MyNonInteractiveStep</processing-class>
<workflow-editable>false</workflow-editable>
</step>
Note: Non-interactive steps will not appear in the Progress Bar! Therefore, your submitters will not even know they are there. However, because they are not visible to your users, you should make sure that your non-interactive step does not take a large amount of time to finish its processing and return control to the next step (otherwise there will be a visible time delay in the user interface).
StartSubmissionLookupStep is a new submission step, available since DSpace 4.0 contributed by CINECA, that extends the basic SelectCollectionStep allowing the user to search or load metadata from an external service (arxiv online, bibtex file, etc.) and prefill the submission form. Thanks to the EKT works it is underpinned by the Biblio Transformation Engine ( https://github.com/EKT/Biblio-Transformation-Engine ) framework.
To enable the StartSubmissionLookupStep you only need to change the configuration of the id="collection" step to match the following
<step id="collection">
<heading></heading> <!--can specify heading, if you want it to appear in Progress Bar-->
<processing-class>org.dspace.submit.step.StartSubmissionLookupStep</processing-class>
<jspui-binding>org.dspace.app.webui.submit.step.JSPStartSubmissionLookupStep</jspui-binding>
<xmlui-binding>org.dspace.app.xmlui.aspect.submission.submit.SelectCollectionStep</xmlui-binding>
<workflow-editable>false</workflow-editable>
</step>
UI compatibility
The new step is available only for JSP UI. Nonetheless, if you run both UIs and want the JSP UI benefit of the new step you can configure it as processing class also for XML as it degrades gracefully to the standard SelectCollectionStep logic
The BTE is a Java framework developed by the Hellenic National Documentation Centre (EKT) and consists of programmatic APIs for filtering and modifying records that are retrieved from various types of data sources (eg. databases, files, legacy data sources) as well as for outputting them in appropriate standards formats (eg. database files, txt, xml, Excel). The framework includes independent abstract modules that are executed seperately, offering in many cases alternative choices to the user depending of the input data set, the transformation workflow that needs to be executed and the output format that needs to be generated.
The basic idea behind the BTE is a standard workflow that consists of three steps, a data loading step, a processing step (record filtering and modification) and an output generation. A data loader provides the system with a set of Records, the processing step is responsible for filtering or modifying these records and the output generator outputs them in the appropriate format.
The standard BTE version offers several predefined Data Loaders as well as Output Generators for basic bibliographic formats. However, Spring Dependency Injection can be utilized to load custom data loaders, filters, modifiers and output generators.
When StartSubmissionLookupStep is enabled, the user comes up with the following screen when a new submission is initiated:
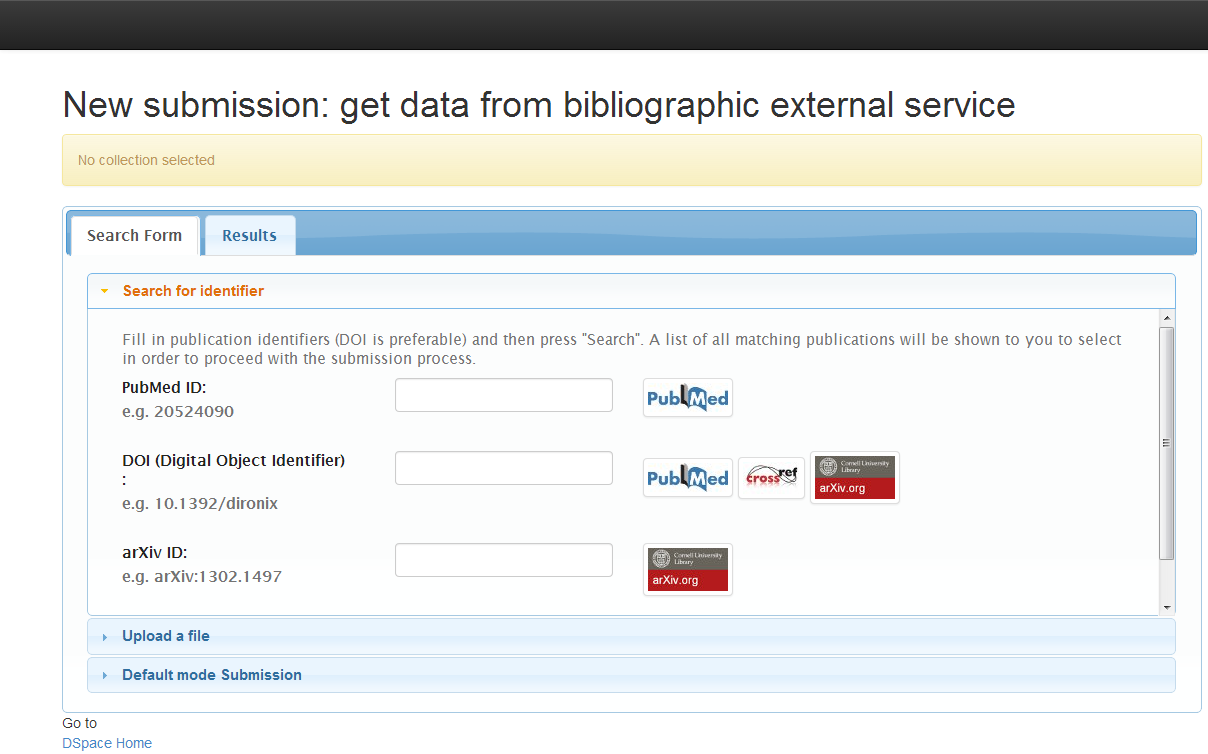
There are four accordion tabs (default configuration hides the third tab):
1) Search for identifier: In this tab, the user can search for an identifier in the supported online services (currently, arXiv, PubMed, CrossRef and CiNii are supported). The publication results are presented in the tab "Results" in which the user can select the publication to proceed with. This means that a new submission form will be initiated with the form fields prefilled with metadata from the selected publication.
Currently, there are four identifiers that are supported (DOI, PubMed ID, arXiv ID and NAID (CiNii ID) ). But these can be extended - refer to the following paragraph regarding the SubmissionLookup service configuration file.
User can fill in any of the four identifiers. DOI is preferable. Keep in mind that the service can integrate results for the same publication from the three different providers so filling any of the four identifiers will pretty much do the work. If identifiers for different publications are provided, the service will return a list of publications which will be shown to user to select. The selected publication will make it to the submission form in which some fields will be pre-filled with the publication metadata. The mapping from the input metadata (from arXiv or Pubmed or CrossRef or CiNii) to the DSpace metadata schema (and thus, the submission form) is configured in the Spring XML file that is discussed later on - you can see a table at the very end of this chapter.
Through the same file, a user can also extend the providers that the SubmissionLookup service can search publication from.
2) Upload a file: In this tab, the user can upload a file, select the type (bibtex. csv, etc.), see the publications in the "Results" tab and then either select one to proceed with the submission or make all of them "Workspace Items" that can be found in the "Unfinished Submissions" section in the "My DSpace" page.
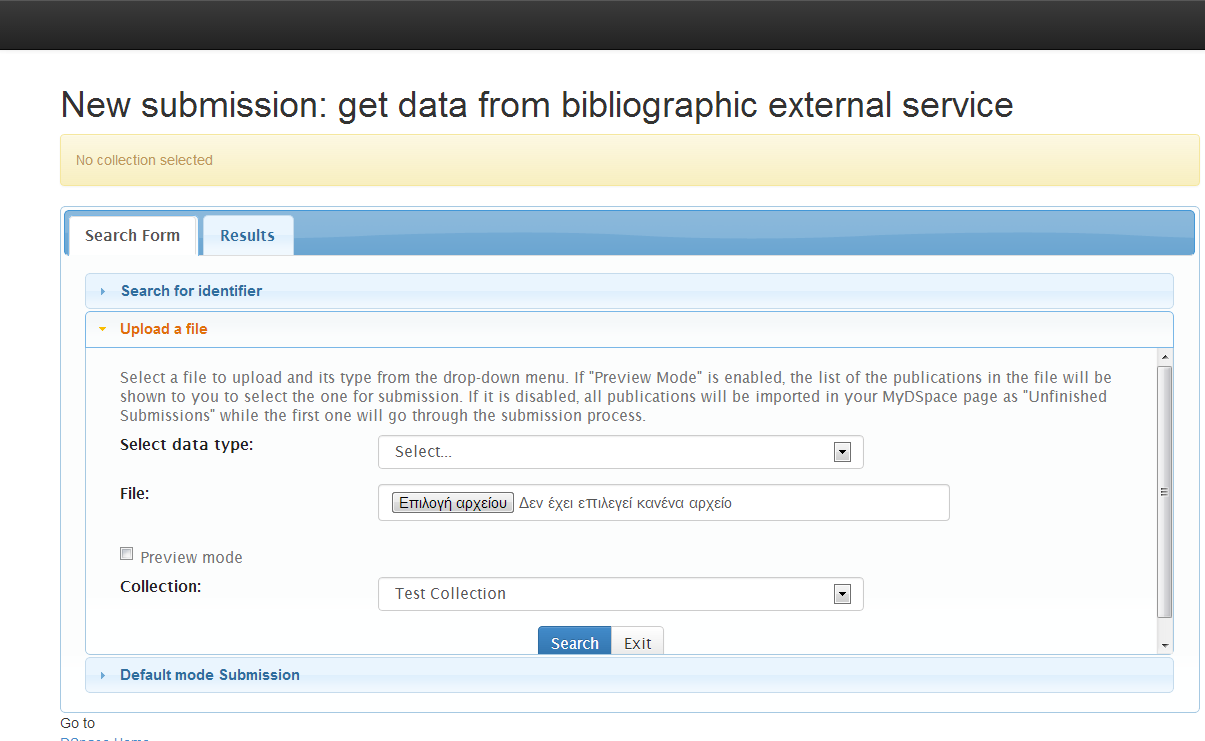
The "preview mode" in the figure above has the following functionality:
"ON": The list of the publications in the uploaded file will be show to the user to select the one for the submission. The selected publication's metadata will pre-fill the submission form's fields according to configuration in the Spring XML configuration file.
"OFF": All the publications of the uploaded file will be imported in the user's MyDSpace page as "Unfinished Submissions" while the first one will go thought the submission process.
(Regarding the pubmed, crossref and arxiv file upload, you can find the attached file named "sample-files.zip" that contains samples of these three file types)
3) Free search: In this tab, the user can freely search for Title, Author and Year in the four supported providers (PubMed, CrossRef, Arxiv and CiNii). By default, the four providers are configured to be disabled for free search but you can enable it via the configuration file. Thus, initially this accordion tab is not shown to the user except for a data loader is declared as a "search provider" - refer to the following paragraphs.
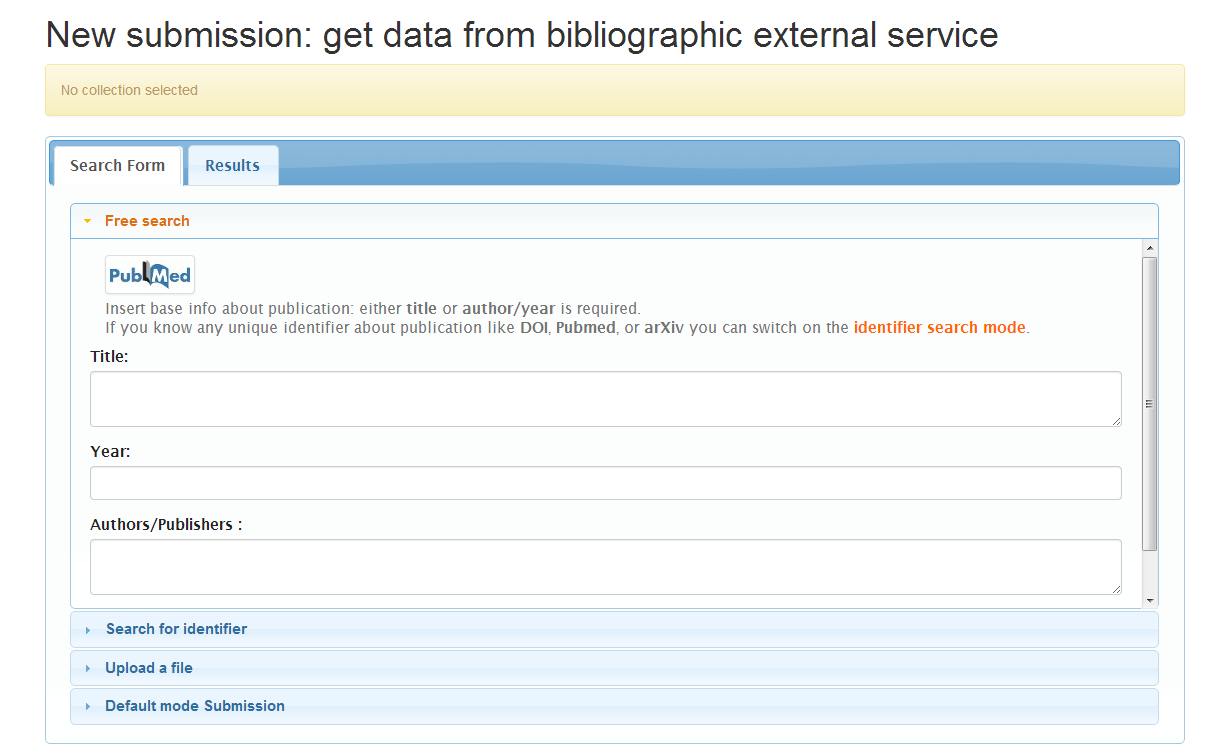
The process is the same as in the previous cases. A result of publications is presented to the user to select the one to preceed with the submission.
4) Default mode submission: In this tab, the user can proceed to the default manual submission. The SubmissionLookup service will not run and the submission form will be empty for the user to start filling it.
The StartSubmissionLookupStep rely on business logic provided by the SubmissionLookup service that can be heavily extended and customized and is build on top of the BTE.
The basic idea behind BTE is that the system holds the metadata in an internal format using a specific key for each metadata field. DataLoaders load the record using the aforementioned keys, while the output generator needs to map these keys to DSpace metadata fields.
The BTE configuration file is located in path: [dspace]/config/spring/api/bte.xml and it's a Spring XML configuration file that consists of Java beans. (If these terms are unknown to you, please refer to Spring Dependency Injection web site for more information.)
The service is broken down into two phases. In the first phase, the imported publications' metadata are converted to an intermediate format while in the second phase, the intermediate format is converted to DSpace metadata schema
Explanation of beans:
<bean id="org.dspace.submit.lookup.SubmissionLookupService" />
This is the top level bean that describes the service of the SubmissionLookup. It accepts three properties:
a) phase1TransformationEngine: the phase 1 BTE transformation engine.
b) phase2TransformationEngine: the phase 2 BTE transformation engine
c) detailFields: A list of the keys that the user wants to display in the detailed form of a publication. That is, when the results are shown, user can see the details of each one. In the detailed form, some fields appear. These fields are configured by this property. Refer to the table at the very end of this chapter to see the available values. This property is disabled by default while the list that is shown commented out is the default list for the detailed form.
<bean id="phase1TransformationEngine" />
The transformation engine for the first phase of the service (from external service to intermediate format)
It accepts three properties:
a) dataLoader : The data loader that will be used for the loading of the data
b) workflow : This property refers to the bean that describes the processing steps of the BTE. If no processing steps are listed there all records loaded by the data loader will pass to the output generator, unfiltered and unmodified.
c) outputGenerator : The output generator to be used.
Normally, you do not need to touch any of these three properties. You can edit the reference beans instead.
<bean id="multipleDataLoader" />
This bean declares the data loader to be used to load publications from. It has one property "dataloadersMap", a map that declares key-value pairs, that is a unique key and the corresponding data loader to be used. Here is the point where a new data loader can be added, in case the ones that are already supported do not meet your needs.
A new data loader class must be created based on the following:
a) Either extend the abstract class gr.ekt.bte.core.dataloader.FileDataLoader
in such a case, your data loader key will appear in the drop down menu of data types in the "Upload a file" accordion tab
b) Or, extend the abstract class or g.dspace.submit.lookup.SubmissionLookupDataLoader
in such a case, your data loader key will appear as a provider in the "Search for identifier" accordion tab
<bean id="bibTeXDataLoader" /> <bean id="csvDataLoader" /> <bean id="tsvDataLoader" /> <bean id="risDataLoader" /> <bean id="endnoteDataLoader" /> <bean id="pubmedFileDataLoader" /> <bean id="arXivFileDataLoader" /> <bean id="crossRefFileDataLoader" /> <bean id="ciniiFileDataLoader" /> <bean id="pubmedOnlineDataLoader" /> <bean id="arXivOnlineDataLoader" /> <bean id="crossRefOnlineDataLoader" /> <bean id="ciniiOnlineDataLoader" />
These beans are the actual data loaders that are used by the service. They are either "FileDataLoaders" or "SubmissionLookupDataLoaders" as mentioned previously.
The data loaders have the following properties:
a) fieldMap : it is a map that specifies the mapping between the keys that hold the metadata in the input format and the ones that we want to have internal in the BTE. At the end of this article there is a table that summarises the fields that are used from the three online services (pubmed, arXiv and crossRef) - which are the ones that the submission lookup step is capable of reading from the online services - and the keys used internally in the BTE.
Some loaders have more properties:
CSV and TSV (which is actually a CSV loader if you look carefully the class value of the bean) loaders have some more properties:
a) skipLines: A number that specifies the first line of the file that loader will start reading data. For example, if you have a csv file that the first row contains the column names, and the second row is empty, the the value of this property must be 2 so as the loader starts reading from row 2 (starting from 0 row). The default value for this property is 0.
b) separator: A value to specify the separator between the values in the same row in order to make the columns. For example, in a TSV data loader this value is "\u0009" which is the "Tab" character. The default value is "," and that is why the CSV data loader doesn't need to specify this property.
c) quoteChar: This property specifies the quote character used in the CSV file. The default value is the double quote character (").
pubmedOnlineDataLoader, crossRefOnlineDataLoader, arXivOnlineDataLoader and ciniiOnlineDataLoader also support another property:
a) searchProvider: if is set to true, the dataloader supports free search by title, author or year. If at least one of these data loaders is declared as a search provider, the accordion tab "Free search" is appeared. Otherwise, it stays hidden.
crossRefOnlineDataLoader and ciniiOnlineDataLoader also have two more properties:
a) apiKey/appId respectively: Both these services need to acquire (for free) an API key in order to access their online services. For CrossRef, visit: http://www.crossref.org/requestaccount/ and for CiNii visit: https://portaltools.nii.ac.jp/developer/en/
b) maxResults: the maximum results that these services will reply with to your search. By default, this property is commented out while the default value is 10 for both services.
(Regarding the file dataloaders, you can find the attached file named "sample-files.zip" that contains samples of all the file types that the corresponding data loaders can handle)
<bean id="phase1LinearWorkflow" />
This bean specifies the processing steps to be applied to the records metadata before they proceed to the output generator of the transformation engine. Currenty, three steps are supported, but you can add yours as well.
<bean id="mapConverter_arxivSubject" /> <bean id="mapConverter_pubstatusPubmed" /> <bean id="removeLastDot" />
These beans are the processing steps that are supported by the 1st phase of transformation engine. The two first map an incoming value to another one specified in a properties file. The last one is responsible to remove the last dot from the incoming value.
All of them have the property "fieldKeys" which is a list of keys where the step will be applied.
In the case you need to create your own filters and modifiers follow the instructions below:
To create a new filter, you need to extend the following BTE abstact class:
gr.ekt.bte.core.AbstractFilter
You will need to implement the following method:
public abstract boolean isIncluded ( Record record )
Return false if the specified record needs to be filtered, otherwise return true.
To create a new modifier, you need to extend the following BTE abstact class:
gr.ekt.bte.core.AbstractModifier
You will need to implement the following method:
public abstract Record modify ( Record record )
within you can make any changes you like in the record. You can use the Record methods to get the values for a specific key and load new ones (For the later, you need to make the Record mutable)
After you create your own filters or modifiers you need to add them in the Spring XML configuration file as in the following example:
<bean id="customfilter" class="org.mypackage.MyFilter" />
<bean id="phase1LinearWorkflow" class="gr.ekt.bte.core.LinearWorkflow">
<property name="process">
<list>
... <old filters and modifiers>...
<ref bean="customfilter" />
</list>
</property>
</bean>
<bean id="phase2TransformationEngine" />
The transformation engine for the second phase of the service (from the intermediate format to DSpace metadata schema)
Normally, you do not need to touch any of these three properties. You can edit the reference beans instead.
<bean id="phase2linearWorkflow" />
This bean specifies the processing steps to be applied to the records metadata before they proceed to the output generator of the transformation engine. Currenty, two steps are supported, but you can add yours as well.
<bean id="fieldMergeModifier" /> <bean id="valueConcatenationModifier" /> <bean id="languageCodeModifier" />
These beans are the processing steps that are supported by the 2nd phase of transformation engine. The first merges the values of multiple keys to a new key. The second one concatenates the values of a specific key to a unique value. The third one translated the three-letters language code to two-letters one (ie: eng to en)
<bean id="org.dspace.submit.lookup.DSpaceWorkspaceItemOutputGenerator" />
This bean declares the output generator to be used which is, in this case, a DSpaceWorkspaceItem generator. It accepts two properties:
a) outputMap: A map from the intermediate keys to the DSpace metadata schema fields. The table below displays the default output mapping. As you can see, some fields, while the are read from the input source, are not output in DSpace since there are no default metadata schema fields to host them. However, if you create the corresponding metadata field registry, you can come back in this configuration to add a map between the input field key and the DSpace metadata field.
b) extraMetadataToKeep: A list of DSpace metadata schema fields to keep in the output
The following table presents the available keys from the online services, the keys that BTE uses in phase1 and the final output map to DSpace metadata fields.
| Arxiv | PubMed | CrossRef | CiNii | BTE Key (phase 1) | Extra Keys created by BTE (phase 2) | DSpace Metadata Field | Appears in Detail Form |
|---|---|---|---|---|---|---|---|
| title | articleTitle | articleTitle | title | title | dc.title | yes | |
| published | pubDate | year | issued | issued | dc.date.issued | yes | |
| id | url | ||||||
| summary | abstractText | description | abstract | dc.description.abstract | yes | ||
| comment | note | ||||||
| pdfUrl | fulltextUrl | ||||||
| doi | doi | doi | doi | dc.identifier | yes | ||
| journalRef | journalTitle | journalTitle | journal | journal | dc.source | yes | |
| author | author | authors | authors | authors | dc.contributor.author | yes | |
| authorWithAffiliation | authorsWithAffiliation | ||||||
| primaryCategory | arxivCategory | dc.subject | yes | ||||
| category | arxivCategory | dc.subject | |||||
| pubmedID | pubmedID | ||||||
| publicationStatus | publicationStatus | ||||||
| pubModel | |||||||
| printISSN | printISSN | issn | jissn | dc.identifier.issn | yes | ||
| electronicISSN | electronicISSN | jeissn | |||||
| journalVolume | volume | volume | volume | ||||
| journalIssue | issue | issue | issue | ||||
| language | language | language | dc.language.iso | yes | |||
| publicationType | doiType | subtype | dc.type | yes | |||
| primaryKeyword | subjects | keywords | allkeywords | dc.subject | yes | ||
| secondaryKeyword | keywords | allkeywords | dc.subject | yes | |||
| primaryMeshHeading | mesh | allkeywords | dc.subject | yes | |||
| secondaryMeshHeading | mesh | allkeywords | dc.subject | yes | |||
| startPage | firstPage | spage | firstpage | ||||
| endPage | lastPage | epage | lastpage | ||||
| printISBN | pisbn | dc.identifier.isbn | yes | ||||
| electronicISBN | eisbn | ||||||
| editionNumber | editionnumber | ||||||
| seriesTitle | seriestitle | ||||||
| volumeTitle | volumetitle | ||||||
| publicationType | |||||||
| editors | editors | dc.contributor.editor | yes | ||||
| translators | translators | dc.contributor.other | yes | ||||
| chairs | chairs | dc.contributor.other | yes | ||||
| naid | naid | ||||||
| ncid | ncid | ||||||
| publisher | publisher | dc.publisher | yes |
I can see more beans in the configuration file that are not explained above. Why is this?
The configuration file hosts options for two services. BatchImport service and SubmissionLookup service. Thus, some beans that are not used in the first service, are not mentioned in this documentation. However, since both services are based on the BTE, some beans are used by both services.
All content on the LYRASIS Wiki is licensed under the CC BY (Attribution) license![]() , unless otherwise noted.
, unless otherwise noted.
2 Comments
Nestor Oviedo
In section Item type Based Metadata Collection, there should be a notice about the visibility and required's behaviour:
- about visibility: it will be honored. This means that the field will be displayed based on dc.type's value and visibility scope.
- about required: the field will be required only when it was visible (depending on dc.type's value and visibility scope)
Brian Freels-Stendel
Reportedly, non-dc value pairs can be defined with the following structure: <schema>_<element>[_<qualifier>]
Example value pairs open tag:
<value-pairs value-pairs-name="myschema_author_ghostwriter" dc-term="author">
Add to section: Adding Value-Pairs.