
VIVO Documentation
Old Release
This documentation relates to an old version of VIVO, version 1.9.x. Looking for another version? See all documentation.
This release includes an updated ORCiD integration that can use the ORCiD v2 API. Note that ORCiD are planning to shut down the v1.x API endpoints.
Note that the configuration options have been changed, and you will need to update your runtime.properties.
The only options that are required now are:
# orcid.clientId = 0000-0000-0000-000X
# orcid.clientPassword = 00000000-0000-0000-0000-000000000000
# orcid.webappBaseUrl = http://localhost:8080/vivo
# orcid.externalIdCommonName = VIVO Cornell Identifier
# orcid.apiVersion = 2.0
# orcid.api = sandbox
orcid.apiVersion is simply the version value (e.g. 1.2, 2.0), and orcid.api is just "release" (for the production API), and "sandbox" for the sandbox.
Retrieval of Person information has been improved so that any search that returns people is faster.
For any sites wishing to participate in the Direct2Experts federated site - http://direct2experts.org/ - VIVO now includes the necessary endpoints. Please see the Direct2Experts websites for more information on how to participate.
Isomorphic tests for TDB now handle all of the specialized integer types (NonNegative, Positive, etc) that TDB maps to an internal structure.
Performance for TDB triple stores is improved as the Graph URIs are now cached in the RDF Service.
Version 1.9.2
Upgraded GEMET integration to use SSL web service
Upgraded LCSH integration to use current web service
Problem with creating new items
Add dependencies for ORCID integration
Spaces in prefix definitions
Responsiveness of Capability Map
Add Turtle support to file graph loader
schema.org errors on profile pages
Maven character set issues on Windows
Maven correctly sets Java 1.7 version
Use background RDFService correctly
Improvements
Bug Fixes
To address the desire for improved expert finding features in VIVO, we are pleased to introduce a capability map. This feature allows you to search for research areas, and see the relationship between them and the researchers.
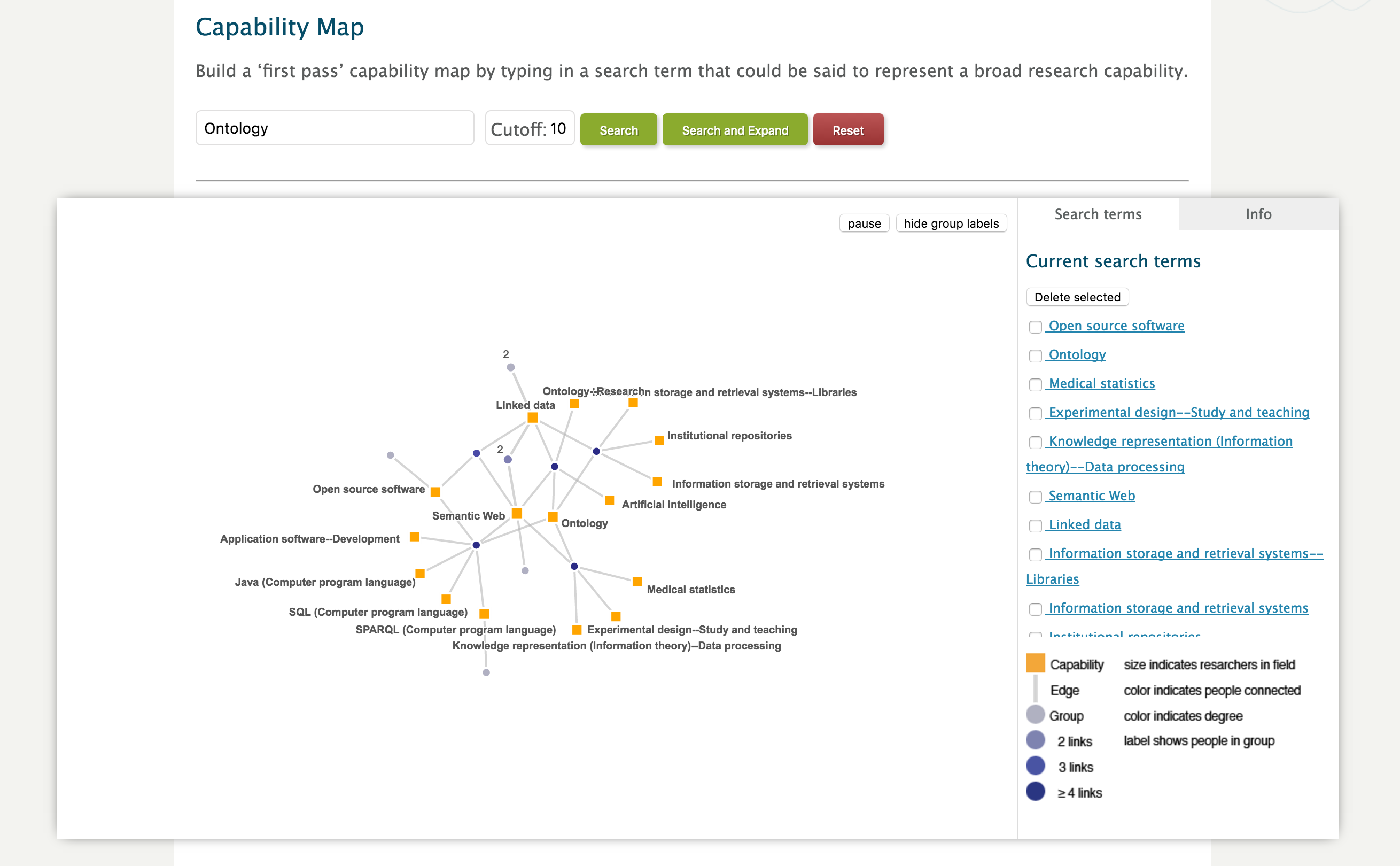
Initially developed at the University of Melbourne, the code has been updated to remove dependencies on third party search engines. In this implementation, it is using the improved visualisation architecture that was introduced in 1.8.1. This means that the results are coming straight out of the triple store; however, the results may be subject to caching, in the same way as the Map of Science, Temporal Graph, etc.
Notes for Upgrading
The capability map is only linked to from the menu bar. As this is configured through the triple store, and the initial definitions are in a file that only gets loaded the first time VIVO is run, upgrading applications will not have the link present.
To access the capability map in an upgraded VIVO, you need to browse to the following url path:
<vivo>/vis/capabilitymap
This can be added to an existing application's menu bar via the Site Admin pages. See Upgrading VIVO for details.
Initial implementation provided by: Simon Porter, Matěj Korvas, Martin Kwok, and Melissa Makin; University of Melbourne.
Adapted for VIVO 1.9 by: Graham Triggs; DuraSpace.
For better indexing and discoverability of your VIVO installation, a sitemap generator is included - in this release, only profile pages are included in the sitemap.
Additionally, citation meta tags are included on the pages of works.
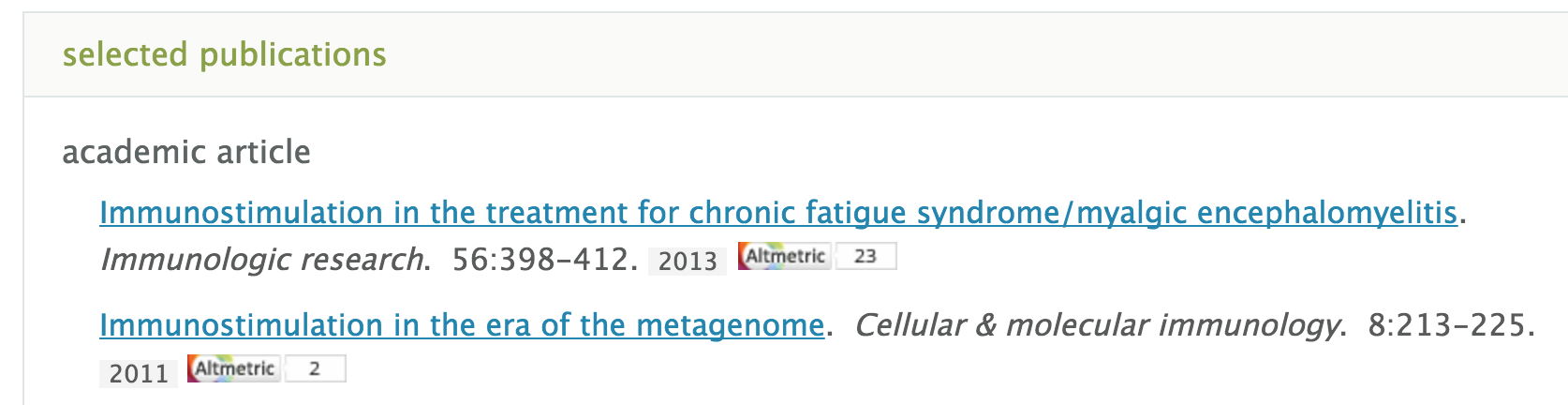
Following the addition of AltMetric badges to publications with DOIs in 1.8.1, the support has been expanded to cover PubMed IDs and ISBNs.
Also, it is now possible to see AltMetric badges on the publication lists within a profile page.
To make it easier for new developers to get started with VIVO, the custom Ant scripts have been replaced with standard Maven project structures.
Both Vitro and VIVO have been migrated. As a developer, when you clone the projects from GitHub, you should place them in directories next to each other. E.g.:
/projects
/Vitro
/pom.xml
/api
/....
/VIVO
/pom.xml
/api
/...
With this layout, you only need to tell your IDE to load or import the pom.xml in the "VIVO" project, and it will automatically load in all of the other projects, including Vitro, setting up your IDE ready to start work with full autocompletion, etc.
As a result of the move to Maven, there is now an "installer" project, which will assemble the application and home directories, and copy them to your Tomcat and installation / home directories.
The installer will automatically download all of the necessary dependencies - including pre-built Vitro and VIVO code - in order to complete the installation.
This installer also provides a natural place for sites to add their customisations: e.g. a custom theme or even additional Java classes in the web application; RDF in the home directory, etc.
The image processor for uploading and generating thumbnails has been replaced with a new library. As a result, there are no known OpenJDK incompatibilities.
Note: It is advised that you use Java 8 for the best performance.
When upgrading, you will need to update your applicationSetup.n3 in order to use the new Image Processor.
Thanks to Brian Lowe, there are significant improvements writing data to the triple store, with an updated inferencer batching changes in memory.
There are also minor improvements to graph comparison code (improve startup time for large graphs), and memory reductions for the caching of data in the visualisations.
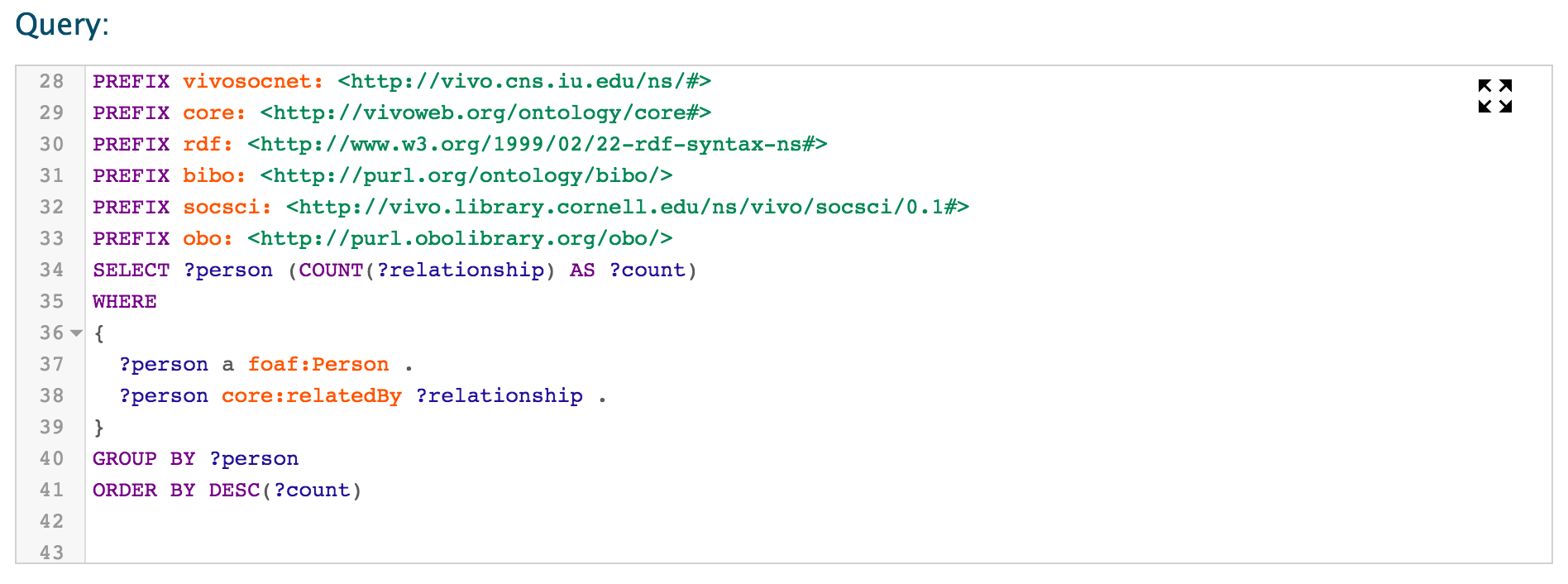
The YASQE highlighting editor for SPARQL has been incorporated into the SPARQL Query page, thanks to a contribution from Ted Lawless.
Ariel David Moya Sequeira, IT Alkaid Consulting S.A.
Stephan Zednik, Rensselaer Polytechnic Institute
Christian Hauschke, Bibliothek der Hochschule Hannover
Roberto J. Rodrigues, Universidade Federal do Rio de Janeiro
Benjamin Gross, UNAVCO
Chad Nelson, Temple University Library
Brain Lowe, Ontocale
Ted Lawless, Thomson Reuters
Graham Triggs, DuraSpace
Nate Prewitt, CU Boulder
Jim Blake, Cornell
Tim Worrall, Cornell
Rebecca Younes, Cornell
Huda Khan, Cornell
Joe McInerney, Cornell
John Fereira, Cornell
Alvin Hutchison, Smithsonian
Simon Porter, Digital Science / University of Melbourne
Matěj Korvas, University of Melbourne
Martin Kwok, University of Melbourne
Melissa Makin, University of Melbourne
Features
Improvements
Bug Fixes
Other
All content on the LYRASIS Wiki is licensed under the CC BY (Attribution) license![]() , unless otherwise noted.
, unless otherwise noted.