How VIVO differs from a spreadsheet
VIVO stores data as RDF individuals – entities that are instances of OWL classes and that relate to each other through OWL object properties and have attributes represented as OWL datatype property statements. Put very simply,
- Classes are types – Person, Event, Book, Organization
- Individuals are instances of types – Joe DiMaggio, the 2014 AAAS Conference, Origin of Species, or the National Science Foundation
- Object properties express relationships between to individual entities, whether of the same or different types – a book has a chapter, a person attends an event
- Datatype properties (data properties for short) express simple attribute relationships for one individual – a time, date, short string, or full page of text
Every class, property, and individual has a URI that serves as an identifier but is also resolvable on the Web as Linked Data.
A triple in RDF has a subject, a predicate, and an object – think back to sentence diagramming in junior high school if you go back that far.
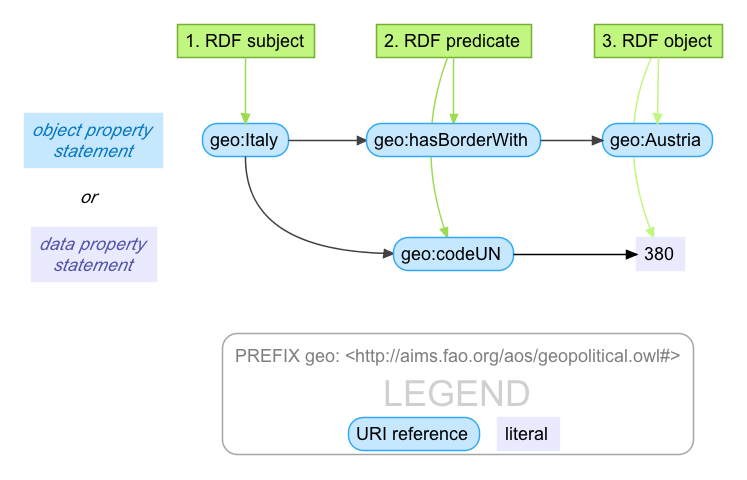
So far all this would fit in a spreadsheet – one row per statement, but never more than 3 columns.
This may not be the most useful analogy, however, since you can't say very much in a single, 3-part statement and your data will be much more complex than that. A person has a first name, middle name, and lastname; and a title, a position linking them to a department; many research interests; sometimes hundreds of publications, and so on. In a spreadsheet world you can keep adding columns to represent more attributes, but that soon breaks down.
But let's stay simple and say you only want to load basic directory information in VIVO – name, title, department, email address, and phone number.
| name | title | department | phone | |
|---|---|---|---|---|
| Sally Jones | Department Chair | Entomology | sj24@university.edu | 888 777-6666 |
| Ruth Ginsley | Professor | Classics | rbg12@university.edu | 888 772-1357 |
| Sam Snead | Therapist | Health Services | ss429@university.edu | 888 772-7831 |
Piece of cake – until you have a person with 2 (or 6) positions (it happens). Or two offices and hence two work phone numbers.
VIVO breaks data apart in chunks of information that belong together in much the same way that relational databases store information about different types of things in different tables. There's no right or wrong way to do it, but VIVO stores the person independently of the position and the department – the position has information a person's title and their beginning and ending date, while the department will be connected to multiple people through their positions but also to grants, courses, and other information.
VIVO even stores a person's detailed name and contact information as a vCard, a W3C standard ontology that itself contains multiple chunks of information. More on this later.
Storing information in small units removes the need to specify how many 'slots' to allow in the data model while also allowing information to be assembled in different ways for different purposes – a familiar concept from the relational database world, but accomplished through an even more granular structure of building blocks – the RDF triple. There are other important differences as well – if you want to learn more, we recommend The Semantic Web for the Working Ontologist, by Dean Allemang and Jim Hendler.
Where VIVO data typically comes from
Cleaning data prior to loading
Matching against data already in VIVO
Doing further cleanup once in VIVO